This is the second part of a two-part series covering how to copy data from DynamoDB to S3 and query it with Athena.
- Part 1: Query DynamoDB with SQL using Athena - Leveraging DynamoDB Exports to S3
- Part 2 (this article): Query DynamoDB with SQL using Athena - Leveraging EventBridge Pipes and Firehose
DynamoDB is a highly scalable NoSQL database, but it has limited query capabilities like any NoSQL database. By exporting data to S3 and querying it with Athena using SQL, we can combine the scalability of DynamoDB with the flexibility of SQL queries. This offers a truly serverless approach to SQL queries.
The solution is built using CDK and TypeScript. It covers both single- and multiple-table designs.
Stream DynamoDB data to S3 using EventBridge Pipes & Firehose, then query with with Athena using SQL.
Real-Time Data Flow to S3
In Part 1, we explored how to use DynamoDB's native export to S3. While that works well for certain use cases, it falls short when you need near-real-time data. In Part 2, we’ll demonstrate a solution to stream new DynamoDB data to S3 in near real-time using EventBridge Pipes and Firehose.
An added advantage of using Firehose over DynamoDB’s native export feature is that Firehose can convert the data to efficient formats, such as Parquet, which optimizes both storage and Athena query performance. You can also filter the data, so not all records need to be exported.

Downsides and Considerations
Delay
Exporting DynamoDB data via EventBridge Pipes and Firehose, we can achieve real-time data storage in S3, albeit with some delay. How much delay depends on which batching configuration you set on Firehose. Firehose batch the data to store multiple records into one file. This is beneficial regarding cost, and most of all, it is great for Athena because it performs better when working with larger files.
Append-Only Nature
Data in S3 is stored in an append-only format. If a record is deleted in DynamoDB, it won’t be removed from S3. Instead, you will need to store a record with a “deleted” flag and adjust your queries to account for this. Similarly, updates in DynamoDB are stored as new records, meaning that your Athena queries must be designed to retrieve the latest version of a record, which can add complexity. Those kinds of queries could be slow and expensive. But Athena is cheap, so this is not a problem if you do not have terabytes of data.
Duplicate Records
There’s no guarantee that data transferred to S3 will not duplicate records. EventBridge Pipes and Firehose do not ensure exactly-once delivery, so some records may be duplicated. Athena appears like an SQL database, but it is not. It has no constraints on the primary key, as you would subconsciously expect. And the whole process of transferring data is not idempotent, which means that it can produce duplicates. So, on most aggregate queries, you will need to use a DISTINCT SQL statement or similar approach.
While Athena is cost-effective, handling duplicate records or complex queries may lead to performance trade-offs, especially with large datasets.
Sample Project
We will have two DynamoDB tables:
CustomerOrder- Follows a single-table design and stores the following entities:CustomerOrderOrder Item
Item- Stores the items sold in the store. It does not use single-table design.
For simplicity, we will assume that orders, customers, and order items cannot be updated or deleted, but items can.
We want the following daily reports:
- Total earnings each day
- Most expensive order of the day with all ordered items
- Total inventory count
Architecture
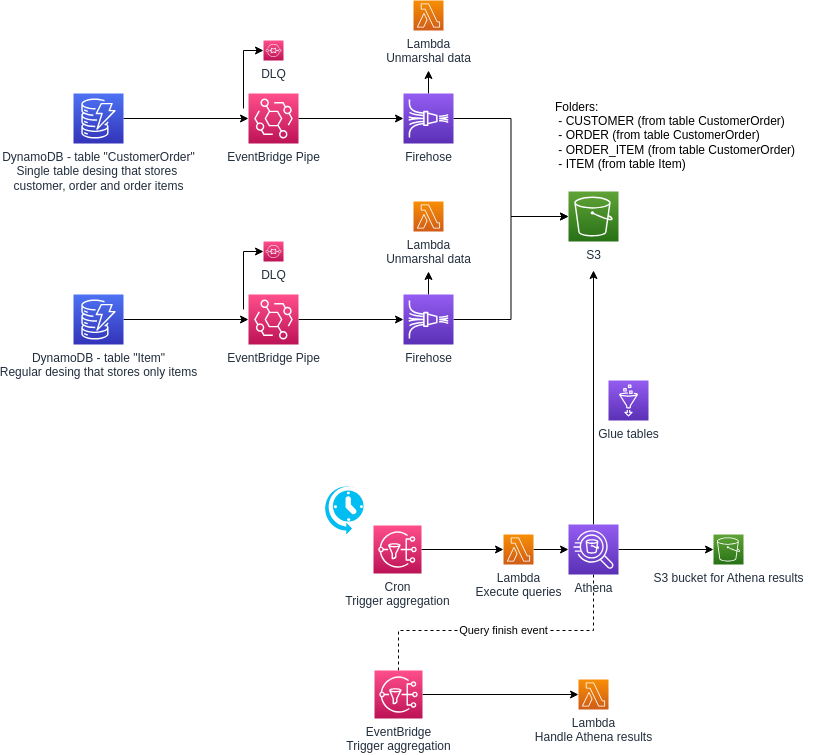
EventBridge Pipes picks data from DynamoDB Streams and sends it to Firehose, which then stores the data in an S3 bucket. A Lambda function within Firehose handles data transformation (e.g., unmarshalling the DynamoDB data and formatting it for storage).
We use AWS Glue to define schemas that Athena can use to query the data.
The single table design in DynamoDb is quite popular, so we will cover how to transfer tables to multiple partitions in Athena, which behave like tables. We will also cover multiple-table design. Table CustomerOrder, which stores customer, order, and order items, will be used as an example of a single table design. Table Item will be a regular table with items that we sell.
The solution is written with CDK and TypeScript is available on GitHub.
The project includes a script to insert random data into DynamoDB. Run npm run insert-sample-data in the script folder.
Connecting DynamoDB Streams to Firehose with EventBridge Pipes
Check the code here.
This is a reusable CDK construct. You can also add filters to specify which types of events (e.g., inserts, updates, deletions) or entity types are sent to S3. Pay attention to the dead-letter queue (DLQ) configuration, which captures records that cannot be processed.
Firehose
Check the code here.
This is also a reusable CDK construct. We configured Firehose to use the Parquet format, which both compresses data to save costs and improves query performance in Athena. Additionally, we'll use partitioning to store data in a folder structure that looks like entity_type/year/month/day. entity_type part allows you to create separate Glue tables for each entity type. The partitions based on year, month, and day also serve as Glue partition keys, further enhancing Athena's query efficiency when filtering by date.
Lambda Transformation in Firehose
Check the code here.
DynamoDB data is structured in a format like this:
{
"Item": {
"itemId": {
"S": "5c2c18ae-8e42-428f-a057-5fd3441dbcf8"
},
"category": {
"S": "Electronics"
},
"price": {
"N": "100.65"
},
"name": {
"S": "Intelligent Granite Car"
}
}
}
To store this data in Parquet format, it must first be transformed/unmarshalled into a standard JSON format.
Although EventBridge Pipes supports some basic transformations that do not require Lambda, it only works with string properties.
Unmarshalling:
const dynamoDbData = unmarshall(
data.dynamodb.NewImage ?? data.dynamodb.OldImage
);
Add a deleted flag to mark records that have been deleted in DynamoDB, allowing us to filter them out during querying:
if (!data.dynamodb.NewImage && data.dynamodb.OldImage) {
dynamoDbData.deleted = true;
}
Add entity_type, year, month, day to enable organizing the folder structure in S3:
if (entityType) {
delete dynamoDbData.ENTITY_TYPE;
dynamoDbData.entity_type = entityType;
}
if (dynamoDbData.date) {
dynamoDbData.year = parseInt(dynamoDbData.date.substring(0, 4));
dynamoDbData.month = parseInt(dynamoDbData.date.substring(5, 7));
dynamoDbData.day = parseInt(dynamoDbData.date.substring(8, 10));
}
Queries
We have two Lambda functions to manage Athena queries. The first Lambda is triggered by a cron job to start the query, and the second is triggered by an EventBridge event when the query completes. This Lambda currently logs the results but can be extended to store them in a database. Athena's results are returned in a not-so-nice structure. I wrote a helper to transform them to JSON.
Query 1: Total earnings each day:
WITH "order" AS (
SELECT DISTINCT *
FROM "${process.env.GLUE_TABLE_ORDER}"
),
"order_item" AS (
SELECT DISTINCT *
FROM "${process.env.GLUE_TABLE_ORDER_ITEM}"
)
SELECT year, month, day, SUM(oi.price * oi.quantity) AS total
FROM "order" AS o
INNER JOIN "order_item" AS oi
ON oi.order_id = o.order_id
WHERE year = ?
AND month = ?
AND day = ?
GROUP BY year, month, day
Note how we excluded the duplicates.
Query 2: Most expensive order of the day with all ordered items:
WITH "order" AS (
SELECT DISTINCT *
FROM "${process.env.GLUE_TABLE_ORDER}"
),
"order_item" AS (
SELECT DISTINCT *
FROM "${process.env.GLUE_TABLE_ORDER_ITEM}"
),
"customer" AS (
SELECT DISTINCT *
FROM "${process.env.GLUE_TABLE_CUSTOMER}"
)
SELECT o.order_id,
c.customer_id,
c.name AS customer_name,
SUM(oi.price * oi.quantity) AS total,
ARRAY_AGG(
CAST(
CAST(
ROW(oi.item_id, oi.item_name, oi.quantity, oi.price)
AS ROW(item_id VARCHAR, item_name VARCHAR, quantity INTEGER, price DOUBLE)
) AS JSON)
) AS items
FROM "order" AS o
INNER JOIN "order_item" AS oi
ON oi.order_id = o.order_id
INNER JOIN "customer" AS c
ON c.customer_id = o.customer_id
WHERE year = ?
AND month = ?
AND day = ?
GROUP BY o.order_id, c.customer_id, c.name
ORDER BY total DESC
LIMIT 1
The results are interesting. You can nest data inside the record:
[{
"orderId": "dadff567-97c6-48b9-8ff1-9239e6a68a8c",
"customerId": "835c34ff-2278-4940-b725-85f0354b6af1",
"customerName": "Gene Gottlieb",
"total": 2795.45,
"items": [
{
"item_id": "eb577495-4609-4395-ab1e-1808d3b14feb",
"item_name": "Incredible Soft Salad",
"quantity": 8,
"price": 139.45
},
{
"item_id": "ca1ab8dd-c660-4851-925d-294370cc29a1",
"item_name": "Electronic Metal Table",
"quantity": 9,
"price": 186.65
}
]
}]
Query 3: Total inventory count:
SELECT COUNT(DISTINCT i.item_id) AS total_items
FROM "${process.env.GLUE_ITEM_TABLE}" AS i
LEFT OUTER JOIN (SELECT DISTINCT item_id
FROM "${process.env.GLUE_ITEM_TABLE}"
WHERE deleted = true) AS i_deleted
ON i_deleted.item_id = i.item_id
WHERE i_deleted.item_id IS NULL
Note how we excluded deleted items and ignored the duplicates.
Alarms
Be sure to set up alarms for key components such as the DLQ, EventBridge Pipes, and Firehose. For Firehose, you can use this article.
For simplicity, we’ve omitted them from this sample, but they are crucial in a production environment.
Other Resources
While writing this article, I stumbled upon a similar article, Partitioned S3 Bucket from DynamoDB, by Benjamen Pyle that you might find interesting.