
This is the first part of a two-part series covering how to copy data from DynamoDB to S3 and query it with Athena.
- Part 1 (this article): Query DynamoDB with SQL using Athena - Leveraging DynamoDB Exports to S3
- Part 2: Query DynamoDB with SQL using Athena - Leveraging EventBridge Pipes and Firehose
We will build two solutions using AWS CDK and TypeScript, covering both single-table and multiple-table designs.
Unlocking New Possibilities
The DynamoDB is a NoSQL database, and that fact comes with both the good and the bad. Among others, the good is that it is ultimately scalable; the bad is that it has limited query capabilities. You can squeeze out some additional query capabilities with a single-table approach, but it is still not comparable to any SQL database. However, for reporting, the SQL query language is extremely useful or almost essential.
One option is to copy data to an SQL database and execute queries there. However, if the database is large, this can be impractical or too expensive. A more scalable solution is to transfer data to S3 and query it with Athena using SQL, which we will explore in this article.
Export DynamoDB to S3 and query with Athena using SQL, unlocking powerful, scalable, and serverless data analyticsShare on LinkedIn
This approach is ideal for serverless solutions where the amount of data or cost makes an SQL database impractical. Athena is a powerful alternative and can be very cost-effective. At $5 per terabyte of queried data, it is significantly cheaper than provisioning an SQL instance capable of handling that volume. However, if you're running many queries, Athena may become expensive. Athena is best for creating offline reports. It's usually too slow for direct synchronous responses to users.

There are several ways to copy data from DynamoDB to S3, but the most useful and serverless-friendly are:
- Using native full or incremental exports from DynamoDB to S3
- Using EventBridge Pipes and Firehose for a near real-time copy of the data
This article focuses on the first approach. The second approach will be covered in Part 2. We will look at both solutions in the context of single-table and multiple-table designs.
Single-Table Design
The principle of single-table design is to store multiple types of entities into one table and leverage the capability of the mainly global secondary index and sort keys to archive many patterns that are not possible with regular key-value stores. Single-table design comes with a price. It is much harder to understand the data in the database, and the approach is often criticized as overengineered. The most common reason is that developers take "single table" literally, using one table for the whole system. They also try to use every possible pattern instead of adapting the approach to the current project's needs.
No matter which design strategy you follow, single-table design presents a variety of adaptable patterns that can be utilized with any approach and are often essential for building complex systems.
Other Options to Query DynamoDB Data
There are alternative ways to query DynamoDB using SQL-like syntax. One option is PartiQL, a SQL-compatible query language built into DynamoDB. However, PartiQL can be risky because it may trigger a full table scan for queries that aren't resolvable using indexes, leading to high costs and slow performance.
Another approach is to deploy the Athena DynamoDB connector and use Amazon Athena to query DynamoDB directly. While this can offer more flexibility in querying, it can also become expensive for similar reasons—queries that scan large portions of the data can quickly drive up costs.
Native Export from DynamoDB to S3
Native export from DynamoDB to S3 offers two options: full and incremental exports. We will cover both approaches. To use either, you need to enable Point-in-Time Recovery on the DynamoDB table.
There isn't much configuration required for exporting data. You also cannot apply filters to select which records to export.
For full export, you can export the data state at a specific point in time within the last 35 days. In this article, we will export the data in its current state.
Incremental export allows you to specify a time range, which is useful for daily, weekly, or monthly exports. You cannot export more than 24 hours of data in a single export. With incremental export, you can choose between "New and old images" or "New images only", which defines whether you want to obtain just the late values or also the previous ones.
Two export formats are available: DynamoDB JSON and Amazon Ion.
DynamoDB JSON looks like this:
{
"Item": {
"itemId": {
"S": "5c2c18ae-8e42-428f-a057-5fd3441dbcf8"
},
"category": {
"S": "Electronics"
},
"price": {
"N": "100.65"
},
"name": {
"S": "Intelligent Granite Car"
}
}
}
Amazon Ion is a superset of JSON. It looks like this:
$ion_1_0 {
Item: {
itemId: "98f18524-7e1d-4455-b128-3c6c8b368ddb",
category: "Clothing",
price: 124.2,
name: "Recycled Rubber Mouse"
}
}
We will use Amazon Ion. The structure looks nicer, and the data is a bit smaller.
You might think you can create a full export initially and then switch to incremental exports, but this is not straightforward because the data formats are different. Full export and incremental export data have different structures, with incremental export data being contained in additional properties NewImage and OldImage.
For an example of full export, see the Ion sample above.
Example of incremental export:
$ion_1_0 {
Record: {
Keys: {
itemId: "08259c1a-c325-4482-a5af-7fdd87e0aa57"
},
Metadata: {
WriteTimestampMicros: 1730037149965399.
},
NewImage: {
category: "Clothing",
itemId: "08259c1a-c325-4482-a5af-7fdd87e0aa57",
name: "Electronic Plastic Cheese",
price: 199.85
},
OldImage: {
category: "Accessories",
itemId: "08259c1a-c325-4482-a5af-7fdd87e0aa57",
name: "Leather Wallet",
price: 49.99
}
}
}
Incremental export data has additional properties, NewImage and OldImage, that hold new records and previous versions of the record.
Two approaches are most suitable:
Full export
This is great if you need to run queries only once. If you need periodic exports, this approach works if your database is not enormous (but can still be big). You export everything and then execute your queries on the data in S3. You can read more about the approach here.
Incremental export only
With this approach, you should do exports either immediately upon creating the database or within 35 days of the first data insertion. It has structure with the
NewImageandOldImageparts, as mentioned above. Note that no data is ever deleted from S3, so you'll need to create queries that use only the most recent data. Leveraging theOldImage, you can construct queries that exclude deleted records, as we will show in the sample.
Sample Project
We will have two DynamoDB tables:
CustomerOrder- Follows a single-table design and stores the following entities:CustomerOrderOrder Item
Item- Stores the items sold in the store. It does not use single-table design.
For simplicity, we will assume that orders, customers, and order items cannot be updated or deleted, but items can.
We want the following daily reports:
- Total earnings each day
- Most expensive order of the day with all ordered items
- Total inventory count
Architecture
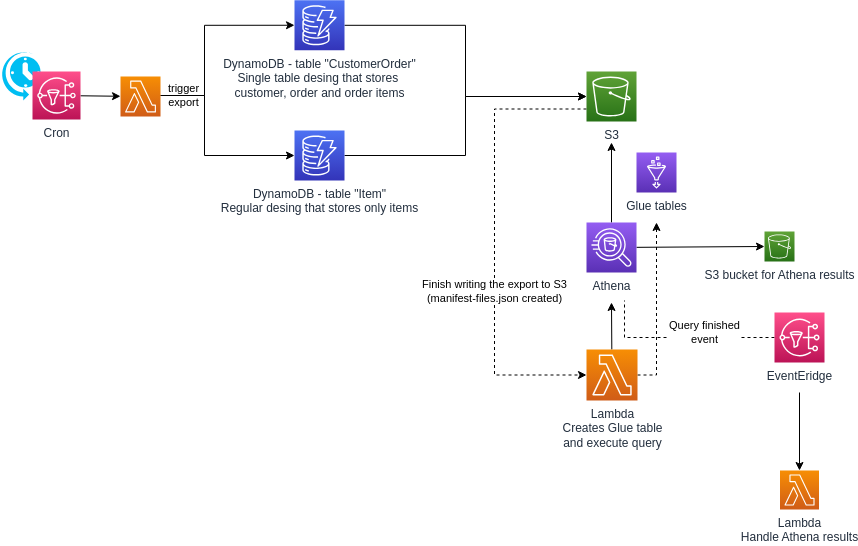
A cron job triggers either a full or incremental export from DynamoDB to S3 once a day. Unfortunately, no EventBridge event is triggered when the export finishes, but we can detect the creation of the manifest-files.json file in the S3 bucket, which happens at the end of the export. This S3 event triggers a Lambda function. The Lambda function (re)creates the Athena/Glue table and then runs the Athena SQL query for the reports.
The solution has two variants: full export or incremental. Two stacks are created, one for each solution. The solution, written with AWS CDK and TypeScript, is available on GitHub.
The project includes a script to insert random data into DynamoDB. Run npm run insert-sample-data in the script folder.
Triggering the Export
Check the code here.
Export is initiated using a simple SDK call.
let exportCommand = new ExportTableToPointInTimeCommand({
TableArn: tableArn,
S3Bucket: bucketName,
S3Prefix: `${tableName}/`,
ExportType: exportType,
ExportFormat: ExportFormat.ION,
IncrementalExportSpecification: {
ExportFromTime: exportFromTime,
},
});
let exportResponse = await dynamoDBClient.send(exportCommand);
Detecting Export Completion
We detect the completion by monitoring for the manifest-files.json file in the S3 bucket. Check the CDK code here.
databaseBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(athenaQueryStartFunction),
{ suffix: "manifest-files.json" }
);
Table Creation
Table creation depends on whether the export is full or incremental.
Here is an example for a table based on full export. View the complete code here.
CREATE EXTERNAL TABLE item (
Item struct <itemId: string,
category: string,
name: string,
price: decimal(10,2)
>
)
ROW FORMAT SERDE 'com.amazon.ionhiveserde.IonHiveSerDe'
LOCATION 's3://${dynamoDBExportBucket}/${dynamoDBTableName}/AWSDynamoDB/${exportId}/data/'
TBLPROPERTIES ('has_encrypted_data'='true');
Tables needs to be recreated after each export, because there is a completely new location of the data. You might want to delete the old exports from S3.
For incremental exports, the schema differs due to the NewImage and OldImage data structure. View the complete code here.
CREATE EXTERNAL TABLE item (
Record struct <NewImage: struct <itemId: string,
category: string,
name: string,
price: decimal(10,2)
>,
OldImage: struct <itemId: string>
>
)
ROW FORMAT SERDE 'com.amazon.ionhiveserde.IonHiveSerDe'
LOCATION 's3://${dynamoDBExportBucket}/${dynamoDBTableName}/AWSDynamoDB/data/'
TBLPROPERTIES ('has_encrypted_data'='true');
Tables do not need to be recreated, because we are just adding data with incremental exports.
Queries
We have two Lambda functions to manage Athena queries. The first Lambda (full export version, incremental export version) that starts the query is triggered by the S3 event mentioned above when export finishes. The second is triggered by an EventBridge event when the query completes. This Lambda currently logs the results but can be extended to store them in a database. Athena's results are returned in a not-so-nice structure. I wrote a helper to transform them to JSON.
The queries vary depending on whether the export is full or incremental.
Full Export Queries
Check the code here.
Query 1 for full export: Total earnings each day:
Since this is a single-table design, we first use CTE (the WITH statement) to create nicer tables. From then on, the query is simple.
WITH "customer" AS (
SELECT Item.customerId AS customer_id,
Item.name AS name,
Item.email AS email
FROM "customer_order"
WHERE Item.entity_type = 'CUSTOMER'
),
"order" AS (
SELECT Item.orderId AS order_id,
Item.customerId AS customer_id,
DATE(parse_datetime(Item.date, 'yyyy-MM-dd''T''HH:mm:ss.SSS''Z')) AS order_date
FROM "customer_order"
WHERE Item.entity_type = 'ORDER'
),
"order_item" AS (
SELECT Item.orderId AS order_id,
Item.itemId AS item_id,
Item.itemName AS item_name,
Item.price AS price,
Item.quantity AS quantity
FROM "customer_order"
WHERE Item.entity_type = 'ORDER_ITEM'
)
SELECT o.order_date AS order_date,
SUM(oi.price * oi.quantity) AS total
FROM "order" AS o
INNER JOIN "order_item" AS oi
ON oi.order_id = o.order_id
WHERE o.order_date = parse_datetime(?, 'yyyy-MM-dd')
GROUP BY o.order_date
ORDER BY order_date;
Query 2 for full export: Most expensive order of the day with all ordered items:
-- ...fist part is the same as query 1
SELECT o.order_id,
c.customer_id,
c.name AS customer_name,
SUM(oi.price * oi.quantity) AS total,
ARRAY_AGG(
CAST(
CAST(
ROW(oi.item_id, oi.item_name, oi.quantity, oi.price)
AS ROW(item_id VARCHAR, item_name VARCHAR, quantity INTEGER, price DOUBLE)
) AS JSON)
) AS items
FROM "order" AS o
INNER JOIN "order_item" AS oi
ON oi.order_id = o.order_id
INNER JOIN "customer" AS c
ON c.customer_id = o.customer_id
WHERE o.order_date = parse_datetime(?, 'yyyy-MM-dd')
GROUP BY o.order_id, c.customer_id, c.name
ORDER BY total DESC
LIMIT 1
The results are interesting. The JSON output nests order data within each record for a structured response.
[{
"orderId": "dadff567-97c6-48b9-8ff1-9239e6a68a8c",
"customerId": "835c34ff-2278-4940-b725-85f0354b6af1",
"customerName": "Gene Gottlieb",
"total": 2795.45,
"items": [
{
"item_id": "eb577495-4609-4395-ab1e-1808d3b14feb",
"item_name": "Incredible Soft Salad",
"quantity": 8,
"price": 139.45
},
{
"item_id": "ca1ab8dd-c660-4851-925d-294370cc29a1",
"item_name": "Electronic Metal Table",
"quantity": 9,
"price": 186.65
}
]
}]
Query 3 for full export: Total inventory count:
SELECT COUNT(Item.Itemid) AS total_items
FROM item
Full Export Queries
Check the code for queries for incremental export.
Query 1 and 2 for incremental export
Queries are the same, except for the beginning, where we prepare the tables.
WITH "customer" AS (
SELECT DISTINCT
Record.NewImage.customerId AS customer_id,
Record.NewImage.name AS name,
Record.NewImage.email AS email
FROM "customer_order"
WHERE Record.NewImage.entity_type = 'CUSTOMER'
),
"order" AS (
SELECT DISTINCT
Record.NewImage.orderId AS order_id,
Record.NewImage.customerId AS customer_id,
DATE(parse_datetime(Record.NewImage.date, 'yyyy-MM-dd''T''HH:mm:ss.SSS''Z')) AS order_date
FROM "customer_order"
WHERE Record.NewImage.entity_type = 'ORDER'
),
"order_item" AS (
SELECT DISTINCT
Record.NewImage.orderId AS order_id,
Record.NewImage.itemId AS item_id,
Record.NewImage.itemName AS item_name,
Record.NewImage.price AS price,
Record.NewImage.quantity AS quantity
FROM "customer_order"
WHERE Record.NewImage.entity_type = 'ORDER_ITEM'
)
...
Query 3 for incremental export: Total inventory count:
Since items can be deleted, we need to take that into account and remove them. We also need to ignore duplicates that occur because of updates.
SELECT COUNT(DISTINCT i.Record.NewImage.itemId) AS total_items
FROM "item" AS i
LEFT OUTER JOIN (SELECT DISTINCT Record.OldImage.itemId as item_id
FROM "item"
WHERE Record.OldImage.itemId IS NOT NULL
) AS i_deleted
ON i.Record.OldImage.itemId = i.Record.NewImage.itemId
WHERE i.Record.NewImage.itemId IS NOT NULL
AND i_deleted.item_id IS NULL