A steep learning curve is the main drawback of building serverless applications on AWS. AWS could do a better job of making an ideal developer experience. We’ve seen some small steps of improvement, but the ideal platform is still far away. Not only that, the development experience could be better, but there are also many cases where the actual behavior goes against the initial developer expectation, and you can easily lose data or get unexpected results without a deep understanding of AWS services. A good platform should abstract the details from the developer. But that is not the case with AWS.
Designing a serverless system can be complex, and without knowing the internal workings of the services, you could easily lose the data.
Let’s start with common ground. In more traditional, non-event-driven systems, you write data directly to the database, and losing data means that there is an issue with the database. But serverless systems are, in a large portion, event-driven systems, and data is eventually consistent. Putting data/events into such a system does not necessarily mean that it is immediately written to the database. It can be passed between several event busses, pub-sub, and event streaming systems … and, in most cases, ends up in a NoSQL database, like DynamoDB, which is by their nature eventually consistent. If you put data/event into such a system and it does not eventually end up at the destination or you do not get it when retrieving from the database, you have a problem. The data could also be lost, duplicated, you get older records than expected, etc. This article’s title mentions losing data, but we will actually cover all these cases.
1. Duplicate and Unordered Events
This is the most common way for your data to be deformed.
Most services do not guarantee order and exactly once delivery. SQS FIFO and SNS FIFO provide that, and stream-based systems like DynamoDB Streams and Kinesis Streams provide order guarantees. SQS FIFO and SNS FIFO are less scalable and more expensive than their regular counterparts, and you should only use them if you have solid reasons to.
In most cases, you should expect the events to be triggered unordered, and they can be duplicated. Handling unordered messages means that you should not override the new record with the older record received afterward. Handling duplicated events means that the system should be idempotent. For example, if you receive a charge on your bank account, you should check that the same transaction was not already processed.
Most AWS services do not guarantee order and exactly once delivery. You should ensure your system is idempotent.
Although most developers know this, it goes against basic intuition, and we quite easily forget that Lambda subscribed to SQS, SNS, and EventBridge can be triggered multiple times with the same payload. But there is the same case with other, less-used services. If you save data to S3 via Kinesis Firehose and queried by Athena, the same problem can occur. Kinesis Firehose can duplicate records. Athena behaves like an SQL database, but that does not mean that it has all the constraints that SQL databases have. Records with the same ID can quite easily be duplicated, and queries that do not anticipate that would return wrong results.
Athena behaves like an SQL database but does not have constraints. Records with the same ID can be duplicated.
2. Bulk Operations
This is probably the most dangerous thing that developers often forget because it goes against basic intuition. What would you expect if one or more records failed when bulk inserting into SQS, SNS, EventBridge, DynamoDB, or Kinesis? Well, if you expected the SDK to throw an error, so the problem is logged, and maybe the whole process can be retried or dropped to some Deal Letter Queue (DLQ) ... you would be wrong. SDK does not throw an error. It just returns the list of failed records. You will not know if you have lost the data if you do not check that list. The problems go further with read operations. If you do a bulk get operation on DynamoDB and do not receive some records, you would expect that the records do not exist. Wrong again. The SDK returns records that it managed to get and also the records that it failed to process (field UnprocessedKeys), but that does not mean that the records are not in the database.
Failed bulk operations using AWS SDK do not throw an error. You might been losing data.
The funny thing is that SDK for EventBridge does not even have a non-bulk operation. So even if you put one record in, you still use a bulk approach and may lose the data if you do not check the result (FailedEntryCount field).
Failure with bulk operations may happen more frequently than with regular operations because sending a lot of data could overload the system, which could fail/throttle on more records. You should customize the settings on how the SDK communicates with the service and how the retry and backoff mechanism works. You should do that for DynamoDB, where default settings are not optimal, especially when using Lambda. You can read more about that here and here.
3. Eventually Consistent
As mentioned, with event-driven architecture and especially a NoSQL database (e.g., DynamoDB), which are, in essence, eventually consistent, you will, in most cases, not know if the database will return the latest data. That is by design in most distributed systems. But it goes against our intuition, especially when using the database.
DynamoDB is eventually consistent, so you might not get the data you just saved.
You could insert and retrieve a record and get a previous record back. For the operations on the Primary Index or Local Second Index, you can force DynamoDB to provide consistent data, which is twice as expensive. But you cannot do that when you query the Global Second Index, which is more often used. The delay until the index is synchronized could be substantial if you insert a lot of data. The easiest solution is not to retrieve data immediately after inserting, but it might not be feasible. For example, in a synchronous process, the user expects the response immediately. If you decide to wait a while, you will not know how long the delay should be.
4. DynamoDB Filter
DynamoDB is one of the more dangerous services that can cause loss of data or receive unexpected results if you do not know how the database works in detail. I already mentioned the bulk operations and eventual consistency. Those are more generic problems.
Issues regarding the DynamoDB filter are unique. DynamoDB has a filter operation, which, as the name implies, removes undesired items from the resultset.
When you use the DynamoDB Filter, you might not get any data, although there are matching records in the database. 😱😱😱
Let's first refresh how DynamoDB works. DynamoDB returns 1MB of data or up to the number of records defined by the limit parameter. Then the filter is applied. Data is then sent to the consumer. If you set the limit to 10 records and set a filter, DynamoDB would retrieve 10 records and then apply the filter. If some or all of those records do not meet the filter criteria, they will not be returned. This means that you will receive less than 10 records or possibly zero, although there could be millions of matching records in the database. You could check the LastEvaluatedKey to see if there are more records, but why would you if your intuition tells you that you received less than the requested 10 records? The same goes even if you do not use the limit. DynamoDB retrieves 1MB of data from the storage, applies the filter, and returns results that could again be empty, although there are matching records in the database. That is clearly stated in the documentation, but if you are new to DynamoDB, that is quite unexpected.
5. Dead Letter Queue Messages are Lost After the Retention Period
A Dead Letter Queue (DLQ) pattern in event-driven / asynchronous system is used to drop messages that failed to process so they are not lost. Those messages should be either inspected manually or by an automatic system and returned ("redrived") to the system when the problem is resolved. But if you are building the automatic system, do not just retry all failed messages because you could cause an endless loop, which would be very expensive.
If the SQS queue is used for DLQ, the records in DLQ are not stored forever. If you do not process them until the retention period is over, they are lost.
Saving data to the Dead Letter Queue might not prevent data loss if you forget to act upon the alarm 🚨 message.
The first thing that you should do when configuring a DLQ is to set it to a maximum retention period and configure an alarm so that you are notified if some messages are dropped there. You should also not forget to configure a subscription to the alarm, which can quite easily be overlooked. Finally, you should also respond to the alarm message, which could be the most problematic part because it involves human intervention. Failing to process the message should occur quite rarely, and once the issue occurs, the person notified may not respond because they may not know or remember what the message is about. There is also a common problem with alert fatigue because of too many messages, and people start ignoring them. This could also happen to experienced teams.
6. A Poison Pill Message Can Also Cause the Following Messages to be Lost
This problem occurs when using FIFO SQS, FIFO SNS, DynamoDB Streams, and Kinesis Streams without configuring DLQ. What happens if you encounter a record, commonly known as a poison pill message, that you cannot process? If the default configuration is used, the record keeps on retrying indefinitely. Those services guarantee the order, so no other record in that FIFO group or Kinesis/DynamoDB Streams shard/partition will be processed. But all those services do not store the data indefinitely. SQS stores it by default for 4 days, extendable to 14 days, DynamoDB Streams for 1 day, extendable to 7 days, and Kinesis Streams for 1 day, extendable to 1 year. So, if the issue with the problematic message is not resolved by then, you will lose all the data older than that, not just that poison pill message.
A Poison Pill Message 💊 can cause the loss of all old data in FIFO SQS, FIFO SNS, DynamoDB Streams, and Kinesis Streams.
Knowing that, you should configure a DLQ where messages will go after several failed retries. But here is a second problem. Those services guarantee order, which is, of course, lost if some messages are skipped.
7. Lagging Behind When Processing Data
Lambda attached to SQS, Kinesis Streams, and DynamoDB Streams is processing the data. What happens when the Lambda cannot keep up because:
- processing is too time-consuming
- downstream service cannot handle the load
- low reserved concurrency
- low maximum concurrency (SQS only)
- small batches
- the data is not sufficiently parallel processed due to hotkeys in DynamoDB
- not enough or unbalanced shards in Kinesis Streams?
In that case, the data is coming faster than it is processing. Records in the system are becoming old and could be older than the retention period (see the part about the Poison Pill). Then you start losing messages.
If you are slow with processing ⌛, you can lose the data in SQS, Kinesis Streams, and DynamoDB Streams if data exceeds the retention period.
You should configure an alarm for metrics that indicate unprocessed messages are becoming old:
IteratorAgefor Lambda attaches to Kinesis Streams and DynamoDB StreamsApproximateAgeOfOldestMessagefor Lambda attached to SQSAsyncEventAgefor Lambdas executed asynchronously
8. Throttling
When the load hits the predefined quotes/limits, the system starts to reject requests. All AWS services have a lot of predefined quotes. Some are soft, meaning that you can increase them by sending a request to AWS. In the asynchronous process, if you configure DLQ, Lambda Destination, or a similar mechanism that the system can use to store rejected messages, later, you can still process them when you resolve the issue, or the load is lower. But in the synchronous process, like HTTP requests hitting API Gateway and then directly database, those requests are lost because the client/user expects the response right away. First, you should configure alarms for all the quotes that you are likely to hit. It is impossible to list them all, but the first one in your mind should be Lambda account concurrency limit. In most accounts, the default limit is 1,000. This is easily hit with a high load. You should do load testing if you intend to build a service that expects a high load. k6 is a grat tool for load testing.
You should do load testing if you intend to build a service that expects a high load.
9. Missing/Misconfigured DLQ and Maximum Retry Exceeded
Without DLQ, when retries are exhausted, you will lose the message. Each service has different ways and different options to configure retries. Another story is configuring DLQ correctly, which is a challenge on its own, and it would be hard to find a better example of a bad developer experience. Let's go step by step. Mostly, it depends on the invocation mode.
The challenge of the day. Try to correctly configure the Dead Letter Queue in AWS. 🫣
Asynchronous invocation:
SNS, EventBridge, S3, and many other services invoke Lambda asynchronously. In that case, you need to configure two DLQs:
- DLQ on the service side (SNS, EventBridge, …) For SNS and EventBridge, only the SQS queue can be configured as DLQ. In DLQ, messages are dropped if the service fails to send them to the target and not if the target fails to process them. If the target is Lambda, it tries to deliver to the internal asynchronous Lambda queue. You will not see many messages in this DLQ. They go here only if the target service is unable to process or permissions are insufficient. Apart from configuring DLQ, you also must pay attention to how the retry mechanism works. This is not the retry mechanism for how many times the target Lambda is retried! It is a configuration of how many times it retries to put a message to the internal Lambda queue, which succeeds almost every time.
- DLQ on the Lambda side In this DLQ, messages go when invoking a Lambda fails. This does not need to be the SQS queue. It can also be an SNS topic. Or it can be replaced or supplemented by newer Lambda Destination, which is a better solution, but the principle is the same. Lambda Destination can also send messages when Lambda succeeds, not just when it fails. Lambda Destination, in addition to SQS, supports sending messages to other destinations like Lambda function, SNS, or EventBridge. Additionally, it provides previously unavailable error details.
Lambda invoked asynchonously: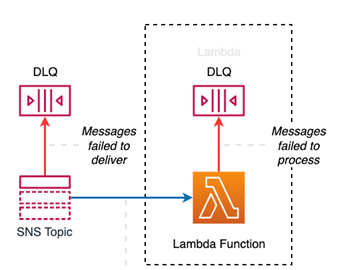
Lambda Destination: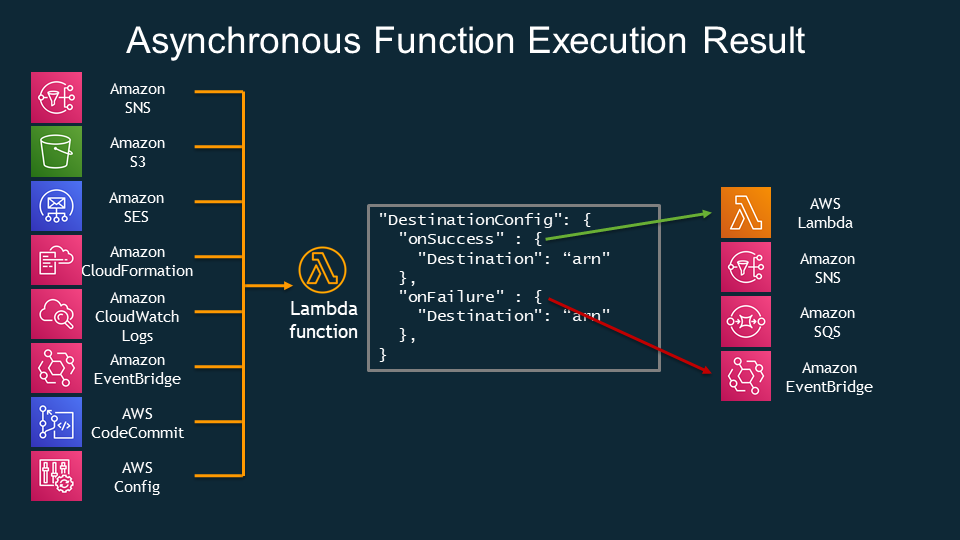
When you execute Lambda functions asynchronously by yourself, you also need to configure DLQ/Lambda Destination, but only the one on the Lambda side because no service is invoking the Lambda.
Lambda attached to SQS (Polling invocation):
In this case, you should configure the DLQ on the SQS side only. DLQ or Lambda Destination on the Lambda side will not work because the Lambda is not executed asynchronously.
Lambda synchronously polling batches of messages from SQS: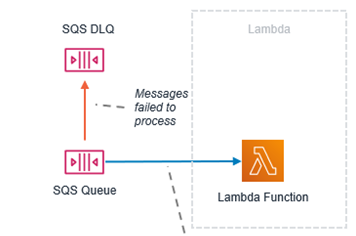
Lambda attached to DynamoDB Streams or Kinesis Streams (Polling invocation):
This configuration is, again, completely different. When configuring the trigger, you can configure DLQ, which can be an SQS queue or SNS topic. You must configure only one DLQ, not two, like on SNS or EventBridge. The DLQ does not receive a failed message nor any error details. You get a position of the message, which you can get from the stream (if it is not past the retention period). The configured DLQ in the AWS console is also visible as Lambda Destination, although this is not an asynchronous Lambda Destination mentioned above, but a stream Lambda Destination. The destination can only be SQS or SNS, but not Lambda or EventBridge. Talk about total confusion!
Synchronous invocation
No DLQ here because it is not an asynchronous operation.
Read more about error handling patterns here and here, retry mechanisms, and configuring DLQ.